© Martin Korneffel,
Stuttgart der
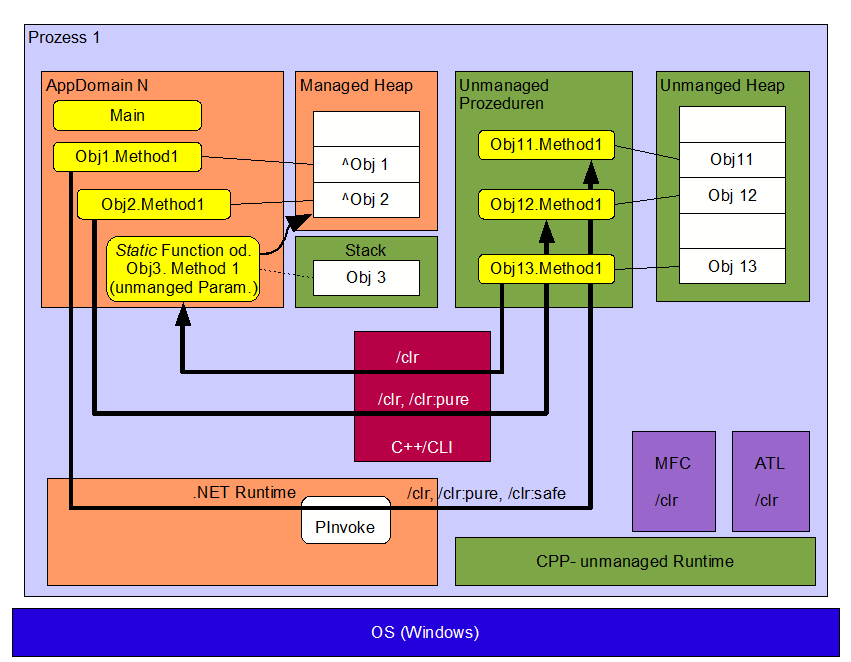
Der Microsoft C++ Compiler ermöglicht Programmierung unter der verwalteten Umgebung als auch unter der klassischen C++ Laufzeit. Mit der Kompileroption /clr können Programme erstellt werden, die während ihres Ablaufes beide Laufzeitumgebungen nutzen. Es wird hierbei von gemischter Programmierung gesprochen. Dies Option wurde geschaffen, um die Migration bestehender C++ Anwendungen in die verwaltete .NET Welt zu erleichtern. So kann eine MFC- Anwendung Problemlos mit /clr kompiliert werden, und damit die .NET Klassenbibliotheken nutzen.
Mit den Optionen /clr:pure und /clr:safe werden die Möglichkeiten, Code aufzurufen, der unter der klassischen Laufzeitumgebung läuft, schrittweise eingeschränkt. Unverwalteter Code ist bezüglich der Stabilität und der Sicherheit im Nachteil gegenüber dem Verwalteten Code. Ziel der Migration besteht aus Sicht des Compilers in den Übergängen von den Optioen /clr → /clr:pure → /clr:safe.
Die Abkürzung CLI steht für Common Language Infrastructure.
|
CLI |
||
|---|---|---|
|
CTS Common Type System |
CLS Common Language System |
CIL Common Intermediate Language |
|
VES Virtual Execution System |
||
Damit aus einem C++ Quelltext eine verwaltete Assembly entsteht, muß bei der Compilation der Schalter /clr aktiviert sein.
Innerhalb des Quelltextes können Typen und Methoden gemischt für die verwaltete und unverwaltete Laufzeitumgebung implementiert werden. Die Bereich mit für die verwaltete Umgebung muß dabei durch #pragma managed ... #pragma unmanaged Blöcke eingelschlossen sein.
|
Typen |
Beispiel |
Erläuterung |
|---|---|---|
|
Referenzen |
nullptr |
Null- Handle |
Bei der Erweiterung der Sprache C++ um neue Schlüsselwörter für die verwaltete Programmierung ging Microsoft ursprünglich nach der Konvention vor, das alle neuen Schlüsselwörter mit dem Präfix doppelter Unterstrich gekennzeichnet wurden. Das führte zu schwer lesbaren C++ Quelltexten.
Ab der Version 2005 beschreitet Microsoft neue Wege: die verwalteten Datentypen werden durch sog. "gespacete" Schlüsselwörter gekennzeichnet. Diese setzen sich i.A. aus zwei, durch ein Leerzeichen getrennte Partikel zusammen.
Diese neue Lösung ist aus ergonomischer Sicht gelungen.
|
Schlüsselwort |
Bedeutung |
Beispiel |
|---|---|---|
ref class |
Klasse, deren Objekte im verwalteten Heap plaziert werden |
ref class SUnit {
public:
SUnit(double pvalue, SUnits punit)
: value(pvalue), unit(punit)
{}
SUnits unit;
double value;
double toMeter();
};
|
value class |
Klasse, deren Objekte auf dem Stack plaziert werden |
|
enum class |
Verwalteter Aufzählungstyp |
enum class SUnits {
s_micro=1,
s_mm=2,
s_cm=3,
s_dm=4,
s_m=5,
s_km=6
};
|
interface class |
Verwaltete Schnittstelle |
|
ref struct |
Datenstruktur, die auf dem verwalteten Heap plaziert wird. Alle Member sind automatisch public |
ref struct Point {
SUnit x, y;
};
|
value struct |
Datenstruktur, die auf dem Stack plaziert wird. Alle Member sind automatisch public |
|
Eine Instanz auf dem verwalteten Heap wird durch sog. handles adressiert.
// Spezieller Operator gcnew erzeugt eine Instanz auf dem verwalteten Heap
// und liefert eine tracking- Handle auf das Objekt zurück
SUnit ^weg1 = gcnew SUnit(1, s_cm);
// Der Operator % liefert die Tracking- Handle eines verwalteten Objektes
// so wie der & Operator für ein unverwaltetes Objekt eine Referenz liefern würde
SUnit ^weg2 = %weg1;Objekte im verwalteten Heap können durch den GC auf andere Speicherplätze während ihrer Existenz verschoben werden. Die Handle wird automatisch durch den GC nach den Verschiebeoperation aktualisert.
Wie bei unverwalteten C++ Pointern erfolgt der Zugriff auf die Member über den -> Operator:
weg1-> value = 1; weg1-> unit = s_dm; double Weg1InMeter = weg1-> ToMeter();
Wie in der unverwalteten Welt existiert auch ein Dereferenzierungsoperator (*):
int ^i = gcnew int(); *i = 99;
In der unverwalteten Welt können mittels Instanzen vom Typ <Typname>& Werte auf dem Stack oder Heap referenziert werden. Diese Instanzen werden als Referenzen bezeichnet
// Referenzen in der unverwalteten Welt int x = 99; int& refx = x; // Durch folgende Anweisung wird der Wert von x incrementiert ! refx++;
Da die Position von Objekte im Speicher in der verwalteten Welt durch den GC während der Laufzeit verändert werden kann, ist die klassische C++ Referenz nicht mehr verwendbar. An ihre Stelle tritt die Tracking Referenz.
Eine Trackingreferenz ist vom Typ <Typname>%. Beispiel:
// Referenzen in der verwalteten Welt int x = 99; int% refx = x; // Durch folgende Anweisung wird der Wert von x incrementiert ! refx++; SUnit ^weg1 = gcnew SUnit(1, s_cm); SUnit ^%refWeg = weg1; // Durch folgende Anweisung wird der Wert von x incrementiert ! refWeg-> value++;
Alle verwalteten Referenztypen werden immer auf dem verwalteten Heap platziert. Jedoch ist es auch möglich in C++, Referenztypen als automatische Variablen auf dem Stack zu instanziieren. Auch hierbei erfolgt die Platzierung auf dem verwalteten Heap und implizit generiert der Compiler eine Trackinghandle, die auf das Objekt verweist. Jedoch unterliegt die Destruktion dem Determinismus automatischer Variablen: die Destruktion setzt ein, sobald der Gültigkeitsbereich der Variablen verlassen wird.
Die Destruktion erfolgt in .NET durch das Dispose Muster: Die Klasse, welche eine Destruktion erfordert, implementiert die IDisposable Schnittstelle, wobei die Destruktionslogik in der Dispose- Methode dieser Schnittstelle verpackt wird. In Sprachen wie C# muß die Dispose- Methode explizit zum Zeitpunkt der Destruktion aufgerufen werden oder durch Blöcke wie using {...} automatisch erfolgen. C++ automatisert diesen Prozess, indem die Basis aller Referenzklassen die IDisposable Schnittstelle implementiert, und der C++ Destruktor einer Klasse auf Dispose abgebildet wird. Der Speicherplatz, den ein Referenztyp belegt wird jedoch erst durch den GC freigegeben, welcher für jedes freizugebende Objekt den Finalisier aufruft. Der Finalizer trägt wie der Destruktor den Namen der Klasse, nur ist ihm anstelle der ~ das ! vorangestellt
public ref class CMeasureS
{
public:
double value;
enum class UnitS { mm, cm, dm, m, km};
UnitS unit;
CMeasureS() {
value = 0;
unit = UnitS::m;
}
// Deterministischer Destruktor
~CMeasureS() {
System::Console::WriteLine(
"Destruktion von CMeasureS {0:N} {1:G}",
value,
unit.ToString());
}
// Finalisirung durch den GC
!CMeasureS() {
System::Console::WriteLine(
"Finalisierung von CMeasureS {0:N} {1:G}",
value,
unit.ToString());
}
:
};
|
|
|
|---|---|
SUnit weg1(1, s_m); |
Platzierung auf dem Stack. Das Objekt wird im verwalteten Heap allokiert. Der Destruktor wird aufgerufen, wenn der Gültigkeitsbereich des Objektes verlassen wird |
SUnit ^weg2 = gcnew SUnit(1, s_cm); |
Platzierung auf dem verwalteten Heap. Referenziert wird über eine Tracking Handle. Der Destruktor wird aufgerufen, wenn ein delete auf der Handle erfolgt. Nach dem delete ist der Finalizer abgeschaltet. Wurde die Handle durch kein delete explizit freigegeben, dann wird durch den GC vor der Speicherfreigabe der Finalizer aufgerufen. |
Werden in abgeleiteten Klassen virtuelle Funktionen überschrieben, so ist dies gegenüber klassischem C++ durch das Schlüsselwort override zu kennzeichnen:
namespace grafik {
ref class CLine : public CFigur
{
public:
CPoint a, b;
virtual void print(CPlotter ^plotter) override {
plotter->print_line(a, b, style);
}
virtual void translate(CPoint ^vec) override {
a.x += vec.x;
a.y += vec.y;
b.x += vec.x;
b.y += vec.y;
}
:
}Eine Besonderheit von C++ besteht in der Möglichkeit der gemischten Programmierung. Dabei kann eine Assembly erstellt werden, in der Code unter Verwaltung der modernen CLR- Runtime (verwaltet), als auch unter der klassischen Runtime (unverwaltet) ausgeführt werden kann. Dabei werden die Übergänge zwischen den beiden Laufzeitumgebungen noch durch spezielle C++ Sprachmittel erleichtert, die im folgenden besprochen werden.
Wertetypen in der verwalteten Welt unterliegen einer ähnlichen Speicherverwaltung (Stack) wie in der unverwalteten. Wenn die Binärformate sich zwischen beiden Welten nicht unterscheiden, dann können die verwalteten Werte durch eine 1:1 Kopie aus den nichtverwalteten Werten erstellt werden und umgekehrt. Man spricht auch von blitfähigen Typen.
Folgende verwaltete Typen sind blitfähig:
void, byte, usigned byte, short, ushort, int, uint, long, ulong, float, double, *(Pointer)
Objekte, die auf dem managed Heap liegen, führen kein ruhiges Leben: der GC kann sie zu jedem Zeitpunkt verschieben, um sich ein großes Stück zusammenhängenden freien Speichers zu besorgen. Werden also Adressen von Objekten an unverwaltete Routinen übergeben, dann könnten diese während der Ausführung der unverwalteten Routinen ungültig werden. Der einzige Ausweg besteht in diesem Falle darin, die zu Übergebenen Objekte zu kopieren, was sich negativ auf die Laufzeit auswirkt.
In C++/CLI kann mittels der pin_ptr<Type> Deklaration ein Speicherblock im verwalteten Heap von den Verschiebeaktionen des GC ausgenommen werden, solange der pin_ptr existiert. Man bezeichnet die durch einen pin_ptr adressierten Objekte auch als fixierte Objekte.
Wenn ein Objekt mittels eines pin_ptr fixiert wurde, dann kann anstelle der Kopie die Referenz an die unverwaltete Routine übergeben werden. Die unverwaltete Routine hat dann Zugriff auf den durch das Objekt belegten Speicherplatz im managed Heap.
Folgendes Beispiel stammt aus der MSDN 2005(ms-help://MS.MSDNQTR.v80.de/MS.MSDN.v80/MS.VisualStudio.v80.de/dv_vccore/html/c2b37ab1-8acf-4855-ad3c-7d2864826b14.htm)
// PassArray1.cpp
// compile with: /clr
#include <iostream>
using namespace std;
using namespace System;
#pragma unmanaged
void TakesAnArray(int* a, int c) {
cout << "(unmanaged) array recieved:\n";
for (int i=0; i<c; i++)
cout << "a[" << i << "] = " << a[i] << "\n";
cout << "(unmanaged) modifying array contents...\n";
for (int i=0; i<c; i++)
a[i] = rand() % 100;
}
#pragma managed
int main() {
array<int>^ nums = gcnew array<int>(5);
nums[0] = 0;
nums[1] = 1;
nums[2] = 2;
nums[3] = 3;
nums[4] = 4;
Console::WriteLine("(managed) array created:");
for (int i=0; i<5; i++)
Console::WriteLine("a[{0}] = {1}", i, nums[i]);
pin_ptr<int> pp = &nums[0];
TakesAnArray(pp, 5);
Console::WriteLine("(managed) contents:");
for (int i=0; i<5; i++)
Console::WriteLine("a[{0}] = {1}", i, nums[i]);
}Die Voraussetzung zur Installation einer Assembly im GAC ist, daß sie einen starken Namen besitzt. Dazu wird sie mit einem privaten Schlüssel. Der öffentliche Schlüssel wird zum entschlüsseln der Signatur muß in der Assembly mitgespeichert werden. Beide Schritte erfolgen durch das signieren. Das Signieren wird in C++ durch den Linker abgewickelt. In den Projekteinstellungen ist dazu unter folgender Option ein Verweis auf die mittels des Tools sn.exe erstellten Schlüsselpaardatei einzutragen:
Projekteigenschaften/Konfigurationseigenschaften/Linker/Erweitert/Schlüsseldatei = [Dateipfad auf die Schlüsseldatei]
C++ ist eine Sprache mit langer Geschichte. Es gibt sehr viele Schalter für den Compiler, und die eingesetzten Bibliotheken wie MFC strotzen nur so von Makros. In einer solchen Umgebung kommt es leicht zu Namenskollisionen, die besonders im Fall von Makros nicht vom Compiler erkannt werden, und dem Entwickler Knobeleien beim Kompilieren bescheren. Beispiele:
Im Unterschied zu C# und VB.NET ist Intellisense unter C++ ein sehr launischer Geselle. Ursache ist die Komplexität der Sprache. Werden Templates instanziiert, dann wirft er in der Regel das Handtuch. Sporadisch taucht Intellisense ab- man muss blind weitertippen und plötzlich ist er wieder da. Daran muß man sich wohl gewöhnen...
Bei der Implementierung einer verwalteten Schnittstelle, die in C# definiert war, kam ich in C++ mit dem errno Makro in Konflikt
public ref class MfcMsgBoxHnd : public mko::ILogHnd { public: // Implementierung der Schnittstelle virtual void OnError(int errno, System::String ^msg) { : }
Der Compiler beschwerte sich unverständlicherweise, das in der Klasse MfcMsgBoxHnd keine Implementierung der IlogHnd::OnError- Methode vorhanden sei. Beim Überfahren des errno- Parameters mit der Maus meldete Intellisense als Typ von errno
#define int* (*)(void)
erno wurde also vom Präprozessor durch ein Makro als Funktionspointer überschrieben- die Signatur von OnError war nun eine völlig andere als von mir angenommen, was den Fehler erklärte. Indem errno in errNr umbenannt wurde, war der Fehler behoben. Das ist nicht wirklich ermutigend ...