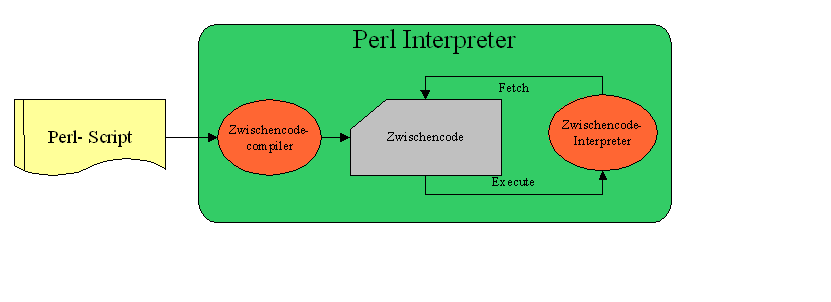
Aufruf des Perl- Interpreters
© TRAC Optische Computer Sensorik, Stuttgart 2002, em@il: trac@n.zgs.de
Perl wurde Ende der 80'er Jahre vom Amerikaner Larry Wall entwickelt als universelle Scriptsprache zur Verarbeitung textueller Informationen sowie zur Systemadministration.
Syntaktisch favorisiert Perl einen Stil, den man als "abstrakte Bilderschrift" bezeichnen könnte: Namen von Systemvariabeln werden auf Sonderzeichen verkürzt (z.B. $] enthält die Versionsnummer des Systems), Backticks (` ... `) schließen auf der Kommandozeile auszuführende Programme ein, während Hochkommata (' ... ') Textkonstanten enthalten.
Die starken Seiten von Perl sind:
Reguläre Ausdrücke
"Allesfressende" Arrays und Hashs (assoziative Arrays)
Komfortable Zugriffsoperatoren- und Funktionen für Arrays und Hashs
hohe Portabilität (Unix, Windows)
Große, frei verfügbare Bibliothek mit allen möglichen Erweiterungsmodulen. So sind existieren z.B. Module für die Administration von W2K- Servern mittels Perl
Perl – Programme werden in ASCII- Code Dateien notiert. Diese erhalten einen Namen nach dem Schema dateiname.pl. Die Datei enthält:
Kommentare (werden durch einen # eingeleitet)
Deklarationen von Variabeln und Funktionen
Perl- Anweisungen
Beispiel:
#! c:\perl\bin\perl # Die erste Zeile enthält einen Verweis auf den Speicherort des Perl- Interpreter $textmeldung = "Hallo"; print $textmeldung, "Administrator"; # Ende
Eine Anweisung stellt einen Programmschritt dar. Anweisungen werden immer durch ein Semikolon abgeschlossen.
$a = 99;
Für die letzte Anweisung in einem Block ist das Setzen des Semikolons jedoch optional:
$a = 99; # In der letzen Anweisung eines Blockes darf das Semikolon weggelassen werden (muss es aber nicht) print $a
Ein scalarer Wert kann von der Kommandozeile mittels des Operators <STDIN> eingelesen werden.
$a = <STDIN>; # Einlesen einer Zeile von der Kommandozeile chomp $a; # entfernen des abschließenden Zeilenumbruchs
Die einfachste Art der Ausgabe stellt die print – Anweisung dar.
print "Hallo Welt";
exit <Rückgabewert> beendet das Programm und gibt einen Wert auf der Befehlszeile aus.
die <Fehlermeldung> beendet das Programm und gibt die Fehlermeldung auf dem Datenstrom STDERR aus.
Als erstes sollte man feststellen, mit welcher Version von Perl gearbeitet wird. Darüber ínformiert folgender Befehl:
c:>perl -v
In der Entwicklungsphase eines Scriptes als auch im Alltag des Admins wird der Interpreter über die Kommandozeile aufgerufen:
c:>perl <Name des Scriptes>
Beim Aufruf des Interpreters gibt es eine Reihe von Optionen. Diese werden nach folgendem Aufruf gelistet:
c:>perl -h
Um ein Script auf Syntaktische Fehler hin zu untersuchen, ohne das es ausgeführt wird, kann die Option -c verwendet werden:
c:>perl -c <Name des Scriptes>
Neben der syntaktischen Analyse ist auch eine eingeschränkte semantische Analyse möglich. Anweisungen, die im Kontext des Programmes keinen Sinn ergeben wie nicht initialisierte Vaiablen etc. werden über die Option -w ausgegeben:
c:>perl -w <Name des Scriptes>
Der Perl- Interpreter kann auch im Debug- Modus gestartet werden. Dabei kann das Programm Schrittweise Zeile für Zeile durchlaufen werden. Nach jeder Zeile kann das Resultat analysiert werden:
c:>perl -d <Name des Scriptes>
Wird der Perl- Interpreter durch einen HTTP- Request aus dem Kontext eines Webserves aufgerufen, dann muß in der ersten Zeile des Scriptdatei hinter dem Kommentarzeichen der absolute Dateipfad zum Interpreter definiert sein:
#!c:\perl\bin\perl
Alles was rechts von eine # Zeichen und dem Zeilenende- Zeichen (\n) in einer Programmzeile steht, wird bei der Übersetzung übersprungen und damit ignoriert. Damit können rechts vom # Anmerkungen des Programmierers (Kommentare) stehen.
$x = sin($y) # Hier steht ein Kommentar, der bei der Übersetzung vom Interpreter übersrpungen wird
Eine weitere Besonderheit von Perl ist, das auch innerhalb von Zeichenketten- Konstanten ausführbare Perl- Kommandos stehen können. Dies dient der komfortablen Textverarbeitung mittels Perl.
Wird einem Variabelnamen ein \ Zeichen vorangestellt, dann wertet Perl den Variabelnamen nicht weiter aus. Beispiel
$x = 29; print "Wird interpretiert als $x"; # Ausgabe: wird interpretiert als 29 print "Wird interpretiert als \$x"; # Ausgabe: wird interpretiert als $x print 'Wird interpretiert als $x'; # Ausgabe: wird interpretiert als $x
Gleichfalls kann das \ benutzt werden, um besondere ASCII- Codes im Quelltext darzustellen. Das wird auch als Escape- Sequenz bezeichnet.
|
Escape- Sequenz |
Beschreibung |
|---|---|
|
\\ |
wird ersetzt durch \ |
|
\ |
wird ersetzt durch '' |
|
\a |
wird durch ein „Glockenzeichen“ ersetzt |
|
\b |
Backspace |
|
\e |
Escape- Zeichen (ASCII 27) |
|
\f |
Formfeed. Sorgt bei älteren Druckern für den Papiervorschub |
|
\n |
Zeilenendezeichen |
|
\r |
Wagenrücklauf |
|
\t |
Tabulator |
|
\xnn |
Wird durch Zeichen mit hex- ASCII- Code nn ersetzt |
Pragma – Module dienen zur Steuerung des Übersetzungsprozesses. Pragmas sind spezielle Module, und werden wie diese eingebunden:
use Pragma;
Strict bewirkt,
alle Variablen müssen mittels my, local oder our deklalriert werden
symbolische Referenzen sind verboten
selbstdefinierten Funktionen muß beim Aufruf ein & vorangestellt werden.
Bewirkt eine ausführliche Ausgabe von Warnungen und Fehlermeldungen.
Perl ist erfolgreich und hat einen längeren Entwicklungprozess hinter sich. Es befinden sich viele Scripte im Einsatz. Um deren korrekte Ausführung nicht in einer neuen Perl- Version zu gefährden, und dennoch dem Entwickler die möglichkeit zu geben, neue Sprachfeatures einzusetzen, kann dieser die neuen Feature selektiv mittelt use feature freischalten. Um z. B. die say- Anweisung zu benutzen, die analog der print-Anweisung Daten ausgibt, und dabei immer einen Zeilenumbruch anhängt, muß folgendes deklariert werden:
use feature 'say';
Schaltet alle Spracherweiterungen einer bestimmten Version frei.
use 5.10.0;
Module (Perl – Bibliotheken) werden nach den Voreinstellungen im aktuellen Verzeichnis bzw. im lib- Verzeichnis der Perl- Distribution gesucht. Durch lib können weitere Pfade definiert werden, in denen der Perl- Interpreter zur Übersetzungszeit nach Modulen suchen kann.
use lib "d:\\trac\\lib's\\perl";
Die Funktionalität von Perl wird durch eine Vielzahl von Modulen erweitert, die ihre Eigenschaften und Methoden in Namensräumen kapseln. Um die Namen der Member abzukürzen, kann der Namespace mittels pragma deklariert werden. Anschließend werden Namen, die im lokalen Namespace nicht auflösbar sind, versucht in den über das Pragma deklarierten Namespaces aufzulösen.
use feature 'say'; $x = Math::Trig::tan(0.9); say '$x=', $x; use Math::Trig; $x = tan(0.9); $y = acos(3.7); $z = asin(2.4); say $x," $y=", $y, $z;
Achtung: Um die nachfolgend beschriebenen Variablen nutzen zu können, muß am Anfang des Perlscripts die Anweisung use English; stehen.
|
Vordefinierte Variabel |
Beschreibung |
|---|---|
|
$] od. $PERL_VERSION |
Versionsnummer und Patchlevel des Perl- Systems |
|
$^O od. $OSNAME |
Das Betriebssystem wird beschrieben, unter dem der Perl- Interpreter läuft. |
|
$^T od. $BASETIME |
Systemzeit in Sekunden, die seit dem 1.1.1970 00:00 GMT vergangen ist |
|
$^X |
Dateiname vom Perlinterpreter |
|
$0 od. $PROGRAM_NAME |
Programmname des Perl- Scripts |
|
$$ od. $PROCESS_ID, $PID |
Prozessnummer, unter der das Script läuft |
|
$^F od. $SYSTEM_FD_MAX |
Maximal Zahl der Systemfiledeskriptoren |
|
$, od. $OUTPUT_FIELD_SEPARATOR od. $OFS |
Enthält das Zeichen, welches bei der Ausgabe einer Liste mittels print zwischen den Listenelementen gesetzt wird |
|
$" od. $LIST_SEPARATOR |
Enthält das Trennzeichen bei der Ausgabe von Arrays mittels print. |
u1-anweisungen.pl:
Beispiele für die Anweisungsklassen Deklaration, Zuweisung, Eingebaute Funktion, Flußsteuerung
Austesten der Pragmas strict, english, diagnostic
|
undef |
Undefiniert. Wird von Funktionen zurückgegeben, um Fehler anzuzeigen |
|
"Hallo Welt" oder 'Hallo Welt' oder qq{Hallo Welt} oder q{Hallo Welt} |
Zeichenketten |
|
1.9999e2 oder 5e-2 |
Gleitkommawert |
|
19 |
Ganzzahliger Wert |
|
Definition |
|
|---|---|
|
Wahrheitswerte TRUE und FALSE |
TRUE und FALSE werden in Perl durch folgende Vereinbarung definiert:
|
Testen aller Varinaten für True/False
Dokumentation: http://perldoc.perl.org/perldata.html
In Perl werden Variablen druch Zuweisen eines Wertes an einen Variablenamen deklariert. Der Typ des zugewiesenen Wertes legt dabei automatisch den Datentyp der Variabel fest.
$eine_festkommavariabel = 1234; $ein_string = "abc";
Standard ist, das alle Variablen innerhalb eines Packages global sind. Erst wenn eine Variable mit den Schlüsselwort my oder local deklariert wird, gilt sie auch als lokale Variable. locale gilt als veraltet, und wird bei Kompilation mit strict nicht unterstützt.
Durch das Pragma strict erst wird erzwungen, das alle Variabeln vor ihrer Verwendung mittels my deklartiert werden müssen.
# Blöcke und Sichtbarkeiten
$x = 99;
my $y = 88;
locale $z = 77;
print "Outer Block \$x= $x\n";
print "Outer Block \$y= $y\n";
{
$x= 199;
my $y = 188;
print "Inner Block \$x= $x\n";
print "Inner Block \$y= $y\n";
}
print "Outer Block \$x= $x\n";
print "Outer Block \$y= $y\n";Scalare Variabeln haben ein $ dem Variabelnamen vorangestellt.
$energie = 1000000;
Arrays (Datenlisten) haben ein @ dem Variabelnamen vorangestellt:
@ein_array = ("Anton", "Berta", "Caesar"); Hash's (assoziative Arrays) wird ein % im Namen vorangestellt:
%auto = {Marke => "Ferrari", Farbe => "rot", Motorleistung_PS => 800 };Jede Variabel in Perl hat immer einen von zwei Zuständen: entweder sie existiert, oder sie ist undefiniert.
Um die Existenz einer Variabel zu prüfen, gibt es die Anweisung defined variabelname. Sie liefert TRUE, wenn die Variabel existiert, sonst FALSE.
$x = 1; $existiert = defined($x) # TRUE, da $x existiert $existiert = defined($y) # FALSE, da $y nicht existiert
Soll eine Variabel nicht weiter verwendet werden, dann kann sie mittesl undef Variabelname vernichtet werden
$x = 1; undef($x); # Variabel vernichten $existiert = defined($x); # FALSE, da $x nicht mehr existiert
Achtung: undef kann als Konstante (s.o.), als auch als Funktion verwendet werden.
Dokumentation: http://perldoc.perl.org/perlvar.html
|
Name |
engl. Name |
Inhalt |
|---|---|---|
|
$_ |
$ARG |
Dient für viele Operatoren als Defaultargument (z.B. reg. Ausdrücke) |
|
$. |
$INPUT_LINE_NUMBER |
Akt. Zeilennummer der Datei, aus der zuletzt gelesen wurde |
|
$/ |
$INPUT_RECORD_SEPARATOR |
Aktuell verwendetes Zeichen zum trennen von Datensätzen beim Lesen aus Dateien (Standard: /n) |
|
$, |
$OUTPUT_FIELD_SEPARATOR |
Zeichen, die beim Ausgeben eines Arrays mittels print zwischen die Werte gesetzt werden (Standard: leer) |
|
$\ |
$OUTPUT_RECORD_SEPARATOR |
Aktueller Trenner für Datensätze bei der Ausgabe mit print (Standard: leer) |
|
$@ |
$EVAL_ERROR |
Fehlermeldung des zuletzt ausgeführten eval Kommandos |
|
$0 |
$PROGRAM_NAME |
Programmname des Scriptes |
|
$[ |
- |
Index des ersten Arrayelements (Standard: 0) |
|
$] |
$PERL_VERSION |
Versionsnummer des aktuellen Perl- Interpreters |
|
$^T |
$BASETIME |
Zeit, die seit dem Start des Programmes, gezählt in Sec seit 1970 |
|
$^X |
- |
Name der ausfühbaren Datei mit dem Perl- Interpreter |
|
$| |
$OUTPUT_FLUSH |
Hat die Variable einen Wert ungleich 0, dann wird nach jedem print die Ausgabe sofort ausgegeben, anstatt sie in Systemeigenen Puffern zwischenzuspeichern |
|
@ARGV |
|
Enthält alle an das Script übergebenen Kommandozeilenparameter |
|
%ENV |
|
Enthält alle Umgebungsvariablen des Betriebssystems (z.B. $ENV{path} == Path- Variable des OS) |
Testen des Verhaltens von globalen und lokalen Variablen in verschachtelten Blöcken
Ausgeben von Variablen nach der Vernichtung
Ausgabe und Indexgrenzen von Arrays beeinflussen
Dokumentation: http://perldoc.perl.org/perlop.html
7 oder 329 oder -33 |
Festkommazahlen (positiv, negativ) |
3.14 oder -12.99 |
Gleitkommazahlen |
2.3e4 oder -3.88e2 oder -3.88e-2 |
Gleitkommazahlen in Exponentialschreibweise |
0xABC123 |
Hex- Zahlen |
0123 |
Oktalzahlen |
Grundrechenarten werden durch die Operatoren +, - , *, / dargestellt.
|
Beispiel |
Ergebniss |
Beschreibung |
|---|---|---|
2 ** 3 |
8 |
Potenz- (Exponential-) Operator |
7 % 3 |
1 |
Modulo- Operator. Bestimmt den Rest einer ganzzahligen Division |
$a = 2; $a++; |
3 |
Postinkrement |
$a = 2; $a--; |
1 |
Postdekrement |
|
Beispiel |
Ergebniss |
Beschreibung |
|---|---|---|
1 == 1 |
true |
Test auf Gleichheit |
1 <=> 2 |
-1 |
Test auf Gleichheit. Wenn $a <=> $b dann -1 für $a < $b, 0 für $a == $b, 1 für $a > $b |
1 < 2 |
true |
|
1 > 2 |
false |
|
Schreiben Sie ein Script, welches Euro in US- Dollar umrechnet.
Bestimmen Sie die kleinste positive darstellbare Gleitkommazahl. Wie genau rechnet Perl ?
|
Beispiel |
Ergebnis |
Beschreibung |
|---|---|---|
1 && 0 |
0 |
Logisches UND |
1 || 0 |
1 |
Logisches ODER |
!0 |
1 |
Logische Negation |
my $metallic = "1"; my $grundpreis = "20000 Euro"; my $MwSt_Satz = 1.16; my $preis = ($metallic ? $grundpreis * 1.1 : $grundpreis) * $MwSt_Satz; |
|
Ternärer Operator |
Logische Aussagen mittels Boolscher Variablen bilden und mittels Operatoren Verknüpfen
Aussagen "Ich fahre Bahn" und "Ich habe einen gültigen Fahrausweis" bilden
Aussage "Ich bin Schwarzfahrer" durch Verknüpfen der Aussagen aus 1.1 bilden
|
Beispiel |
Ergebnis |
Beschreibung |
|---|---|---|
$x = "Es ist" . localtime(time()) . "."; say "Hallo Welt." . $x; |
Es ist ... Hallo Welt. |
Zeichenketten- Verknüpfung. |
print "-" x 4, "\n"; |
---- |
Die links von x stehende Zeichenkette wird n mal wiederholt |
Perl enthält eingebaute relationale Operatoren für Zeichenketten. Jedoch sind für diese spezielle Operatorsymbole definiert.
|
Operator |
Beschreibung |
|---|---|
$a eq $b |
Liefert TRUE, wenn Zeichenkette a identisch mit der Zeichenkette b ist. |
le, ge |
Textuelles kleiner- gleich, größer- gleich |
ne |
Textuelles ungleich |
$a cmp $b |
-1 0 +1, wenn $a kleiner, gleich oder größer als $b ist. |
lt, gt |
Textuelles kleiner, größer |
Dokumentation: http://perldoc.perl.org/perlsyn.html
print "Teuer\n" if ($marke eq "Ferrari");
print "Billig\n" unless ($marke ne "Ferrari");
defined($ARGV[0]) or die "Bitte geben Sie min. 1 Kommandozeilenparameter ein.";
farbe eq "rot" and print("Ein roter Ferrari\n");
if (farbe eq "rot" and marke eq "Ferrari" ) {
print "Ein roter Ferrari\n";
} elsif (farbe eq "gelb" and marke eq "Ferrari") {
# Achtung: elseif wird ohne e (also elsif) geschrieben !
print "Ein gelber Ferrari\n";
} else {
print "Irgend so eine nützliche Familienkutsche\n";
}# Einlesen von Zeilen auf <STDIN> und Ausgabe
while(<STDIN>) {
print;
}# Überspringen aller Zeichen vor dem XML- Element
while (getc ne "<") {}
# Einlesen des Inhalts vom XML- Element
my $tag;
my $char;
do {
$char = getc;
$tag .= $char;
} while($char eq ">")Besuchen aller Elemente einer Liste/Arrays:
foreach <Variabel> (<Liste>) {
<Anweisungsblock>
}Schreiben Sie ein Script, das für ein gegebenes Intervall im Bereich der natürlichen Zahlen alle Primzahlen berechnet.
Dokumentation: http://perldoc.perl.org/perlsub.html
Unterrogramme werden in sub -Blöcken definiert. Parameter werden über das spezielle Array @_ übergeben.
sub &add {
# Die Parameterliste wird im Array @_ übergeben
my ($c, $d) = @_;
return $c + $d;
}Die Länge Anzahl der Zeichen in einem String wird mit der Funktion length($variabelname) bestimmt.
$text = "abc"; $anz_zeichen = lenght($text); # Nach der Anweisung hat $anz_zeichen den Wert 3
Soll ein String durch n Wiederholungen einer Zeichenkette entstehen, dann kann der Multiplikationsoperator x für Zeichenketten eingesetzt werden:
$text = "-neu-" x 3; # Ergebnis: "-neu—-neu—-neu-"
Strings können für Vergleiche bezüglich der Groß/Kleinschreibung invariant gestaltet werden, indem sie Konsequent in reine Groß- oder Kleinschreibung umgesetzt werden:
$text = lc("AbC"); # Ergebnis: ABC
$text = uc("AbC"); # Ergebnis: abcMittels des . Operators können mehrere Zeichenketten zu einer neuen verbunden werden. Werden dabei reine Zahlenwerte mit Zeichenketten verknüpft, so werden diese zuvor in eine Zeichenkettendarstellung umgewandelt:
$neuer_text = $text . "=" . $eine_festkommavariabel; # nach dieser Anweisung hat $neuer_text den Wert
# "abc=1234" Zugriff auf einzelne Zeichen bzw. Textfragmente erfolgt über die Funktion substr string, start [, anz_zeichen]
$ein_zeichen = substr $text, 2, 1; # Nach der Anweisung hat $ein_zeichen den Wert „c“, denn das
# erste Zeichen hat die Position 0Eine der Stärken von Perl ist ein hoher Komfort bei der Textverarbeitung. So kann ein durch substr bestimmte Zeichenkette mittels Zuweisung durch eine zweite ausgetauscht werden.
substr ($text, 1) = "xyz"; # Nach der Anweisung hat $text den Wert „axyzc“
Innerhalb eines Strings kann ein beliebiger Substring durch die Funktion index string, substring [, offset] geortet werden. Liefert -1, wenn Ortung fehlschägt.
$pos = index $text, "yz"; # Nach der Anweisung hat $pos den Wert 2
In einem nummerischen Kontext versucht Perl von links ausgehend eine Zeichenkette soweit wie möglich als Zahl zu interpretieren:
$text = "1.91 Euro";
$wert = 0 + $text; # Wert enthält nach der Zuweisung den Wert 1.91
$hexwert = hex("F"); # Aus der hexadezimalen Zeichenkette wird ein numerischer Wert
$octwert = oct("71"); # Aus der octalen Zeichenkette wird ein nummerischer Wert gneriertUmgekehrt können aus nummerischen Typen wiederum Zeichenketten gewonnen werden, indem der nummerische Typ in einem Zeichenkontext verwendet wird:
$text = "". $wert; # Verwendung in einem nummerischen Kontext $text2 = "$wert"; # Einbettung in eine Zeichenkette
Eine weitere Variante, um aus Zahlen wieder Zeichenketten zu gewinnen besteht in der eingebauten Prozedur sprintf:
$text = sprintf "%10.2f", 3.142356465; # Ausgabe mit einer Breite von 10 und 2 Nachkommastellen
Um Scripts vor unauthorisierter Ausführung zu schützen, können mittels der Funktion crypt einfache Passwortsicherungen eingebaut werden. Funktionsweise:
crypt
Orignalpsaawort ---------------> Hashcode 1234 -+ (Entwurfszeit)
|
<Vergleich>
crypt |
Zugriffspasswort --------------> Hashcode XYZ -+ (Laufzeit)Lesen Sie die Umgebungsvariable Path in eine Variable ein und geben Sie diese aus. Analysieren Sie den Inhalt.
Erweitern Sie das Script aus 1, indem Sie den ersten Pfad extrahieren und Anzeigen.
Erweitern Sie das Script aus 2, indem alle Einzelpfade extrahiert und zeilenweise ausgegeben werden.
Erweitern Sie das Script aus 3, indem alle Laufwerksbuchstaben von C auf D geändert werden
Erweitern Sie das Programm aus 4, indem Sie es durch ein Passwort schützen
Arrays sind Mengen von Speicherplätzen. Die Menge erhält einen Namen, dem ein @ vorangestellt sein muß.
@primzahlen = (2, 3, 5, 7, 11, 17); # Das Array besteht aus 6 Speicherplätzen
Alle Speicherplätze eines Arrays sind durchnummeriert. Die Nummern werden Indizes genannt. Auf ein einzelnes Element wird über einen speziellen Variabelnamen zugegriffen, der sich wie folgt zusammensetzt: $arrayname[index]. Dem Arrayname wird wieder ein $ vorangestellt, so daß eine Varaiabelname entsteht. Diesem werden in eckigen Klammern die Speicherplatznummer hinzugefügt.
$zahl = $primzahlen[3]; # Nach der Anweisung steht in $zahl der Wert 7
Es gibt keine Funktion, die explizit die Anzahl der Elemente eines Array bestimmt. Jedoch kann der größte Index in einem Array wie folgt bestimmt werden:
$anzahl = $#primzahlen; # Nach der Anweisung steht in $anzahl der wert 5
Mittels spezieller Arrayfunktionen werden Datenstrukturen wie Stack und Queue implementiert. Dabei kann mit dem Paar shift/unshift jeweils kein Element am Anfang des Arrays entnommen/hinzugefügt werden. Das Gleiche wird durch das Paar pop/push für das Ende des Array realisiert.
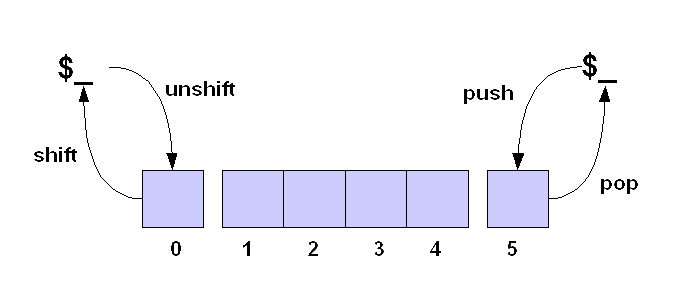
Perl bietet Befehle an, die einen applikativen Programmierstil, wie er. z.B. Lisp vorherrscht, ermöglichen. Der grep- Operator ist dafür ein Beispiel. Er ermöglicht das Anwenden von Operationen auf jedes Arrayelement. Dabei ist im 1. Operanden die Anweisungsliste, und im 2. Operanden das zu Array zu übergeben. In Abhängigkeit von der Operation kann das im Operanden übergebene Array modifiziert werden.
grep <Anweisungsliste>, <Array>;
In der Anwiesungsliste des grep- Befehls wird der Inhalt des aktuell zu bearbeitende Arrayelement über die Variable $_ bereitgestellt:
use strict;
use feature 'say';
say '-' x 40;
say 'primzahlen unsortiert';
my @prim = (13, 2, 7, 3, 5, 11);
# Array als Kommaseparierte Liste ausgeben
my $result = "";
grep {$result .= $_ . ", "} @prim; # Kommaseparierte Liste wird in $result aufgebaut
chop($result); chop($result);
say $result;Perl besitzt einen eingebauten Sortierfunktion. Diese kann auf beliebige Typen angewendet werden dank eines als Parameter übergebbaren Vergleichskriteriums.
<Array_sortiert> = sort <Vergleichskriterium>, <Array>;
Beispiel:
my @prim = (13, 2, 7, 3, 5, 11);
@prim = sort {$a <=> $b} @prim;Im folgenden Beispiel wird eine Liste aus Datenstrukturen, die Autos beschreiben, bezüglich der Motorleistung aufsteigend sortiert.
my %f5 = (typ => 'Ferari', PS => 500);
my %duck = (typ => 'Ente', PS => 25);
my %bug = (typ => 'VW Käfer', PS => 30);
my @cars = (\%f5, \%duck, \%bug);
grep {say $$_{typ}, " mit ", $$_{PS}, " PS"} @cars;
say "Sortiert:";
my @cars_sorted = sort {$$a{PS} <=> $$b{PS}} @cars;
grep {say $$_{typ}, " mit ", $$_{PS}, " PS"} @cars_sorted;Entwickeln Sie eine Programm, welche das Minimum in einem Array bestimmt
Entwickeln Sie ein Programm, welches basierend auf der Minimumsuche aus 1) ein nummersiches Array sortiert
Ersetzen Sie die selbstdefinierte Sortierfunktion durch die in Perl integrierte Sortierfunktion
Nutzen Sie die Funktionen push und pop um ein Script zu
schreiben, welches einfache Klammerausdrücke wie( (3 2)+ 2)*
auswerten kann (Ergebnis = 10). Die Klammerausdrücke liegen
dabei in einem Array Zeichenweise vor : [(|(|3| |2|)|+|
|2|)|*]
Hashs sind ähnlich wie Arrays Mengen von Speicherplätzen. Die Speicherplätze werden durch sog. Schlüssel identifiziert. Schlüssel sind dabei eindeutige alphanummerische Zeichenketten.
%auto = (Marke => "Ferrari", Farbe => "rot", Motorleistung_PS => 800 );
Auf ein einzelnes Element wird über einen speziellen Variabelnamen zugegriffen, der sich wie folgt zusammensetzt: $hashname{''alphanum-index''}.
print $auto{Name}."\n";
print $auto{Farbe}."\n";
print $auto{Motorleistung_PS}."\n";Zum Auslesen aller Schlüssel gibt es die Funktion keys <hash>.
$schluessel = keys %auto; # Das Array schlüssel listet alle Schlüssel von auto auf.
Zum Auslesen aller Werter einer Hash gibt es die Funktion values <hash>.
$werte = values %auto; # Das Array werte listet alle Werte aus dem Hash auto auf.
Zu einem Schlüssel kann mittels exists getestet werden, ob ein Eintrag in der Hash existiert:
print $auto{VW} if exists($auto{VW});Mittels des Perl- Moduls Data::Dumper kann der Inhalt als Perl- Initialisierungsliste dargestellt werden:
use XML::Simple;
use Data::Dumper;
my $href = XMLin('C:\trac\projekt\rbc\2-implementierung\bsp-fehlerprotokoll.xml');
print Dumper($href);Erstellen Sie mittels einer Hash eine Tabelle zur Verwaltung von Kommandozeilenparametern (z.B. -p Passwort -> $cmdparam{-p} = "Passwort")
Erstellen Sie ein Script, welches von der Kommandozeile einen Text einliest, und über den Zeichen des Textes eine Statistik erzeugt (Histogramm). Nutzen Sie bei der Erstellung des Histogramms eine Hash.
Stellen Sie durch eine Hash eine Tabelle dar, die zu jeder römischen Ziffer deren Zahlenwert speichert. Berechnen Sie mit dieser Tabelle den Wert für L
Erweitern Sie das Script aus 1 so, daß für eine Zeichenkette von römischen Ziffern die Summe aller Ziffernwerte berechnet und ausgegeben wird.
Erweitern Sie das Script aus 2 so, daß es fehlertolrant wird (Klein/Großschreibung egal, falsche Ziffernsymbole erweitern Ziffernwerttabelle nicht).
Erweitern Sie das Script aus 3 um ein Hash, deren Schlüssel alle Kombinationen von Zuständen und Eingaben eines EA's darstellen, der Romzahlen verarbeitet, und deren Werte die Folgezustände sind. Die Hash stellt damit die Zustandsüberführungsfunktion des EA's dar.
Mittels der Hash für die Zustandsüberführungsfunktion ist das Script so zu erweitern, daß auch Syntaxfehler beim Aufbau der Romzahlen erkannt werden.
Dokumentation: http://perldoc.perl.org/perlref.html
Referenzen speichern Hauptspeicheradressen von bereits definierten Variabeln. Wie Varaiabeln werden Referenzen durch Zuweisung deklariert. Bsp.:
$ref_x = \$x; # $ref_x speichert die Adresse der Variabel $x
$ref_primzahlen = \@primzahlen; # $ref_primzahlen speichert Adresse vom ersten Element des Arrays
# @primzahlen
$zahl = $$ref_primzahlen[3]; # Zugriff auf das Element mit Index 3 im Primzahlspeicher über Referenz
@kopie = @$ref_primzahlen; # Zugriff auf das gesamte Array über die ReferenzMittels des Speziellen Operator [ ] können namenlose Arrays erzeugt werden, auf die lediglich mittels einer Referenz verwiesen wird:
my $refArr = [ 2, 3, 5, 7 ];
Dieser Operator ist Grundlage für den Aufbau von Datenstrukturen und Objekten
$ref_auto = \%auto; # $ref_auto speichert die Adresse des ersten Schlüssel/Wertepaares
# von %auto
$marke = $$ref_auto{marke}; # Zugriff auf den Wert zum Schlüssel Marke über die Referenz
%kopie = %$ref_auto; # Zugriff auf die gesamte Hash über die ReferenzMittels des Speziellen Operator { } können namenlose Hash's erzeugt werden, auf die lediglich mittels einer Referenz verwiesen wird:
my $refHash = { Name=> "Dagobert", Position => "Chef"};Dieser Operator ist Grundlage für den Aufbau von Datenstrukturen und Objekten.
sub add {
my $s1 = shift;
my $s2 = shift;
return $s1 + $s2;
}
$ref_proc = \&add; # $ref_proc speichert den Einsprungpunkt von sub add
$summe = &$ref_proc (1, 2); # Aufruf der Prozedur add (1, 2) über die Referenz Mittels der in Perl eingebauten Funktion ref <Variabel> kann bestimmt werden, ob eine Variabel eine Referenz ist, und was sie speichert. Speichert die Variabel einen Refenrenzwert dann gehört der Rückgabewert zur TRUE- Menge. Der Rückgabewert zeigt an, was referenziert wird:
|
Rückgabewert im Fall einer Referenz |
|---|
|
SCALAR |
|
ARRAY |
|
HASH |
|
CODE |
|
REF |
|
GLOB |
|
LVALUE |
Hashs, Arrays und Referenzen sind die Bausteine für Datenstrukturen unter Perl. Im folgenden wird ein Fahrzeug samt seiner Insassen durch einen Perl- Datenstruktur beschrieben:
my %f5 = (typ => 'Ferari', PS => 500, Insassen=> ['Ferd Vollgas', 'Dolly Burster']);
say $f5{Insassen}[0], ", ", $f5{Insassen}[1]; # 1) Ausgabe der Insassen
say $f5{Insassen}->[0], ", ", $f5{Insassen}-> [1]; # 2) Gleiches Resultat wie 1) Für technische Berechnungen ist zu jedem Wert die SI- Einheit, in der er gemessen wurde, sowie ein Skalierungsfaktor abzuspeichern.(z.B. die größe der Bildpunkte einer digitalen Kamera wird in 0,1 Micrometern gemessen => Skalierungsfaktor=10, Einheit= Micrometer). Erzeugen Sie eine Datenstruktur, die zu einem Messwert diese drei Größen erfasst.
Schreiben Sie einen Konstruktor für die Datenstruktur aus 1. Stellen Sie mit dem Konstruktor erzeugten Strukturen mittels des Data::Dumpers dar.
Bilden Sie mittels des Konstruktors Messwerte für Pixelgeometrie, Objektiv usw. einer digitalen Kamera. Fassen Sie diese zu einer Struktur namens Kamera zusammen und geben Sie diese mittels des Data::Dumpers aus.
Dokumentation:
Die aktuelle Uhrzeit kann als Unix- Zeitstempel (Zeit in Sekunden, die seit dem 1.1.1970 vergangen ist) mittels der Funktion time() bestimmt werden. Mittels der Funktion gmtime(Zeitstempel) wird aus dem Zeitstempel ein neun- Elementiges Array gewonnen, das den Zeitstempel in Jahr, Monat, ... , Minuten, Sekunden aufsplittet.
$akt_zeit = time(); # Liefert den aktuellen Unix- Zeitstempel ($sec, $min, $hour, $day, $mon, $year, $weekday, yearday, $isdst) = gmtime($akt_zeit); # 0 < $mon < 11, 0 < $weekday < 6
Im folgenden werden Operationen auf Datumswerten anhand der Implementierungen im Modul VBtime ((c) M. Korneffel 2004) beschrieben.
sub CDate {
# Datum der Form "YYYY-MM-DD hh:min:sec" wird in einen Unix- Zeitstempel umgewandelt
my $date = shift;
# Aufteilen in Tag und Zeit
my ($ymd, $t) = split(/\s+/, $date);
my ($yyyy, $mm, $dd) = split(/-/, $ymd);
my ($hh, $min, $sec) = split(/:/, $t);
my $unixdate = eval(timelocal($sec, $min, $hh, $dd, $mm - 1, $yyyy - 1900));
if (not defined($unixdate)) {
die "Es ist ein Fehler aufgetreten: ", $@, "\n";
}
return $unixdate;
}package VBtime;
use Time::Local;
# Konstanten
my %ix;
$ix{sec} = 0;
$ix{min} = 1;
$ix{hh} = 2;
$ix{dd} = 3;
$ix{mm} = 4;
$ix{yyyy}= 5;
$ix{wd} = 6;
$ix{day_of_year} = 7;
$ix{dayligth_saving} = 8;
sub DatePart {
# Aus einem Unix- Zeitstempel wird ein Datumsanteil selektiert
my ($part, $date) = @_;
my @parts = localtime($date);
return 1900 + $parts[$ix{$part}] if ($part eq "yyyy");
return 1 + $parts[$ix{$part}] if ($part eq "mm" or $part eq "day_of_year");
if ($part eq "wd") {
return 7 if ($parts[$ix{$part}] == 0);
return $parts[$ix{$part}];
}
return $parts[$ix{$part}];
}# Konstanten
my %anz_sec_von;
$anz_sec_von{sec} = 1;
$anz_sec_von{min} = 60;
$anz_sec_von{hh} = 3600;
$anz_sec_von{dd} = 24*3600;
$anz_sec_von{week}= 7*24*3600;
sub DateDiff {
# Differenz zwischen zwei Datumsangaben in Zeitintervallen wird bestimmt
my ($int, $von, $bis) = @_;
my $diff = $bis - $von;
return $diff / $anz_sec_von{$int};
}sub DateAdd {
# Zu einem Unix- Zeitstempel wird ein werden n Zeitintervalle hinzuaddiert
my ($int, $anz, $start) = @_;
return $anz_sec_von{$int}*$anz + $start;
}Dokumentation: http://perldoc.perl.org/perlre.html
Der /Muster/- Operators liefert TRUE zurück, wenn in einem String das Muster passt.
$text = "Die Sonne lacht. Der Mond scheint. 4711 ist besser als 0815.";
if ($text =~ /nn/) {
print "nn ist in \$text vorhanden\n"; # Wird ausgeführt, da das Muster /nn/ auf Text passt
} else {
print "nein\n";
}Mittels des tr/<Zeichenklasse>/<Ersatzzeichenklasse>/ können einzelne Zeichen in einem Text ersetzt werden.
$text = "Ein Text in Groß/Kleinschreibung"; $text =~ tr/A-Z/a-z/; # Wandelt den Text vollständig in Kleinschreibung um
Mittels des s/<regExp1>/<regExp>/[optionen] können Textfragmente, auf die regExp1 passt, durch Fragbente, die regExp2 entsprechen ersetzt werden:
$text = "Änderungen werden übertragen. Danach ölen."; $text =~ s/Ä/ae/g;
|
$& |
enthält die bei der letzten Mustersuche erkannte Zeichenkette. |
|
&` oder $PREMATCH |
Enthält die Zeichenkette, die links von der zuletzt bei einer Mustersuche erkannten Zeichenkette steht |
|
&' oder $MATCH |
Enthält die Zeichenkette, die rechts von der zuletzt bei einer Mustersuche erkannten Zeichenkette steht |
|
&N |
Enthält den Text, der durch die n- te Gruppierung in einem Regulären Ausdruck erkannt wurde |
Ein Muster, daß auf alle Whitespace- Zeichen passt:
/s+/
Ein Muster, daß auf alle nicht Whitespacezeichen passt
/S+/
Zerlegen einer Zeichenkette in Worte ohne Splitfunktion:
my $text = "Und sie dreht sich doch !";
do {
$text =~ /\S+\s+/;
print $&, "\n";
$text = $';
} until ($text eq "");print "Zahl" if ($text =~ /^\s*[-|+]{0,1}\s*\d+\s*$/);print "Email gültig" if($text =~ /^\s*[a-z|A-Z|0-9|\-]+@[a-z|A-Z|0-9|\-]+(\.[a-z|A-Z|0-9|\-]+)+\s*$/);
# Der folgende Ausdruck ist non greedy (S. 113).
if ($text =~ /<(\w+)>(.*?)<\/\1>/ ) {
print "Das XML-Fragment ist wohlgeformt\n";
print "Übereinstimmung für $&\n";
print "Text zwischen den wohlgeformten Tags: $2\n";
} else {
print "Das XML-Fragment ist nicht wohlgeformt\n"
}Mittels der Funktion split(<Muster für Trennzeichen>, <textvariabel>) kann ein Text gezielt in seine Bestandteile zerlegt werden. Das Suchmuster ist dabei ein regulärer Ausdruck. Die Bestandteile werden in einem Array zurückgeliefert
@worte = split(/ +/, "Heute ist ein schöner Tag"); # Jedes Element von @worte ist ein Wort aus dem Satz.
Um einen Text nach Worten abzusuchen, die bestimmten Mustern folgen, ist es sinnvoll, diesen erst in ein Arry aus Worte zu zerlegen, und dieses dann mit grep nach einem Muster absuchen zu lassen
# Zerlegen in Wortliste und untersuchen der Worte mit regulären Ausdrücken
@worte = split(/\s+/, $text);
# rausfischen aller Worte, auf die das Muster passt (doppeltes n oder s)
@nn = grep {/(n|s){2}/} @worte;
print "grep:\t@nn\n";Lesen sie die Path- Umgebungvariable ein, und Zerlegen sie diese mittels regulären Ausdrücken in die Einzelpfade. Geben Sie jeden einzelnen Pfad zeilenweise aus.
Geben Sie nur die Pfade aus, die einen Knoten names Programme enthalten
Schreiben Sie ein Script, das Formeln in umgekehrt polnischer Notation (z.B. (1 3.14)+ ) einliest, und in eine Liste aus Token zerlegt (z.B. (, 1, 3.14, ), +)
Vervollständigen Sie den regulären Ausdruck für den Test von Gleitpunktzahlen.
Bauen Sie das Programm zu einem Rechner aus, welches geklammerte Ausdrücke einlesen und berechnen kann.
Verwendet man Module, die im Fehlerfall den Dienst mittels exit oder die quittieren, dann kann das für die eigene Anwendung einen Absturz bedeuten. Um dies zu verhindern, gibt es das Kommando eval( Anweisungen). eval startet einen neuen Instanz des Interpreters, und übergibt an diesen die Anweisungen. Das Ergebnis der letzten Anweisung wird dann zurückgegeben, oder im Falle eines durch exit oder die behandelten Fehlers der Wert undef. Die vordefinierte Variabel $EVAL_ERROR (kurz $@) enthält die Fehlermeldung des zuletzt ausgeführten eval Kommandos.
Bsp.:
use Time::local;
my ($sec, $min, $hh, $dd, $mm, $yyyy) = (0, 0, 0, 30, 2, 2004- 1900);
# Das Fehlerhafte Datum bringt das eigene Script in den folgenden Zeilen nicht zum Absturtz
my $unixdatum = eval(timelocal($sec, $min, $hh, $dd, $mm - 1, $yyyy – 1900));
if (undef($unixdatum) {
print "Es ist ein Fehler aufgetreten: $@\n";
}
# Die folgende Zeile führt zum Absturtz, da das Script durch ein die in timelocal terminiert wird
$unixdatum = timelocal($sec, $min, $hh, $dd, $mm - 1, $yyyy – 1900);
# weiterer Scriptcode
...Dokumentation:
Das Einlesen von Daten durch ein Programm sowie die Ausgabe von Daten erfolgen sequentiell. Dieses Verhalten kann durch das Datenstrommodell beschrieben werden. Ein Datenstrom ist dabei ein sequentieller Strom von Zeichen.
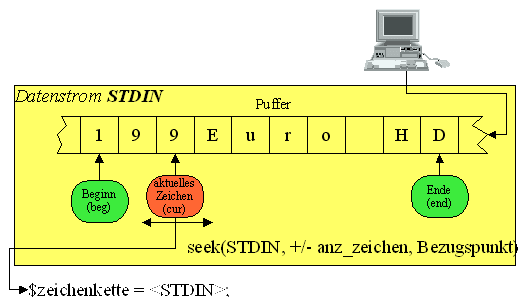
Die Ein- Ausgabe- Datenströme über Befehlszeile werden Standarddatenströme genannt. Das Symbol <STDIN> steht für den Eingabedatenstrom, und das Symbol <STDOUT> für den Ausgabedatenstrom.
Dokumentation: http://perldoc.perl.org/FileHandle.html
Jedem geöffneten Datenstrom wird durch das Betriebssystem eine Dateihandle zugeordnet. In Perl werden die Dateihandles durch Symbole dargestellt, welche einen von Variable und Prozedurnamen unabhägigen Namensraum aufspannen. Konvention ist, diese Symbole durch vollständig Großschreibung darszustellen:
FILE, INPUT etc.
Ähnliche wie bei den Variablen sind die Dateihandles per Default global. Wird die Unterprogrammtechnik verwendet, dann können solche globalen Handles zu bösen Seiteneffekten führen. Einen Ausweg bietet die sog. unbenannte Handles, die durch das Modul Symbol bereitgestellt werden. Die Methode gensym erzeugt Symbole, die als Dateihandle genutzt werden können:
use Symbol;
sub PrimzahlGenerator {
my $dateihandle = gensym();
open ($dateihandle, "primzahlen.txt");
:
}Für die objektorientierte Programmierung von Datei- IO bietet Perl das Modul FileHandle.
use strict;
use feature 'say';
use FileHandle;
# Dateihandle für Eingabe von STDIN (alternativ: Dateinamen) anlegen
my $in = FileHandle->new('-');
# Dateihandle für Ausgabe auf STDOUT (alternativ: Dateinamen) anlegen
my $out = FileHandle->new('>-');
$out-> autoflush(1);
$out-> output_field_separator(":\t");
# Ausgabe
for(my $i= 0; $i< 10; $i++) {
say $i, "Quadrat", $i**2;
} Auf Dateien wird zugegriffen, indem sie an Datenstöme gebunden werden. Dies erfolgt durch die Anweisung open( Datenstromname, openmode.Dateiname).
$ok = open(FILE, 'd:\test.txt') # Wenn erfolgreich, dann ist $ok ungleich 0, und über FILE kann auf
# test.txt zugegriffen werden.
# Manipulationen am Datenstrom
close(FILE);Der openmode bestimmt, ob auf die Datei lesend oder schreibend zugegriffen werden soll, und was passiert, wenn die Datei noch nicht existiert. Dargestellt wird der Openmode durch ein Präfix, das dem Dateinamen vorangestellt ist.
|
Openmode- Präfix |
Beschreibung |
|---|---|
|
name, <name |
Öffnen der Datei zum lesen |
|
>name |
Öffnen der Date zum Schreiben |
|
>>name |
Append if exist: Öffnen der Datei zum Schreiben. Existiert die Datei, werden die Ausgaben am Ende angefügt. Sonst wird eine neue Datei mit dem Namen erstellt. |
|
+<name |
Öffnen zum Lesen und Schreiben |
|
+>name |
Öffnen zum Lesen und Schreiben. Der Inhalt einer bereits bestehenden Datei name wird gelöscht. |
Die Ausgabe in Datenströme erfolgt mittels der Anweisung print DATENSTROM <datenliste>. Datenstrom ist ein zuvor mittels open geöffneter Datenstrom.
print FILE "Datensatz 1\n";
Die aus C bekannte Funktion printf kann ebenfalls in Perl eingesetzt werden:
printf FILE "Summe %5.2f %3s", $betrag, $whg;
|
Name |
Beschreibung |
|---|---|
|
$" oder $LIST_SEPARATOR |
Trennzeichen zwischen Arrayelementen bei der Ausgabe in einem Stringkontext |
|
$, oder $OUTPUT_FIELD_SEPARATOR |
Trennzeichen, welches bei einer Ausgabe mit print zwischen die einzelnen Felder gesetzt wird |
|
$\, oder $OUTPUT_RECORD_SEPARATOR |
Zeichen, welches am Ende der Ausgabe eines Datensatzes ausgegeben wird. Soll z.B. jedes print mit einem Zeilenumbruch abgeshlossen werden, dann kann diese Variable auf "\n" gesetzt werden. |
|
$| oder $OUTPUT_FLUSH |
Enthält die Variable einen Wert ungleich Null, dann wird nach jedem Aufruf von print oder write der Ausgabepuffer geleert |
Dokumentation: http://perldoc.perl.org/perlop.html#I%2fO-Operators
Das Lesen erfolgt mittels des Operators <DATENSTROM>. Im Normalfall list der Operator eine Zeile aus dem Datenstrom ein.
$zeile = <STDIN>; # Es werden alle Zeichen bis einschließlich dem Zeilenendezeichen (\n) eingelesen
Wird jedoch einem Array zugeiesen, dann werden alle Zeilen eingelesen und in jeweils ein eigenes Arrayelement gestellt.
open(TEST, „test.txt“); @alle_zeilen = <STDIN>; # Alle Zeilen aus Test werden eingelesen
$ein_zeichen = getc(FILE);
$num_read = read(FILE, $buffer, $count);
Mittels der Funktion seek kann die Position von der gelesen bzw. in die geschrieben wird, verändert werden:
$result = seek(FILE, $position, $mode);
$position definiert die Position in der Datei, auf die die nächste Lese/Schreiboperation wirkt. $mode definiert, wie aus den Daten in $position die neue Dateizeigerstellung berechnet wird:
|
Wert von $mode |
Bedeutung von $position |
|---|---|
|
0 |
Vom Dateianfang aus wird der Dateizeiger um $position Byte nach rechts verschoben. $position muß einen positiven Wert enthalten. |
|
1 |
Von der aktuellen Position aus wird der Dateizeiger um $position Byte nach links (negativer Wert) oder nach rechts (positiver Wert) verschoben |
|
2 |
Vom Dateiende aus wird der Dateizeiger um $position Byte nach links geschoben. $position muß einen negativen Wert enthalten |
In Multitasking- Umgebungen wie CGI auf einem Webserver muß der Zugriff auf Datein serialisiert werden. Dazu bietet Perl die Funktion flock:
# Exklusiver Zugriff auf Dateien use Fcntl ':flock'; open(FILE, "u35-ini.ini"); print "Datei u35-ini.ini wird gesperrt\n"; flock(FILE, LOCK_EX); # Zugriff sperren print "Bitte geben Sie was ein:"; $in = <STDIN>; flock(FILE, LOCK_UN); # Zugriff freigeben print "Datei u35-ini.ini wurde wieder freigegeben\n";
|
Sperroptionen |
Konstanten |
Bedeutung |
|---|---|---|
|
1 |
LOCK_SH |
Zugriff shared: Aktueller Prozess darf schreiben, alle anderen nur lesen |
|
2 |
LOCK_EX |
Zugriff exclusiv: Nur der aktuelle Prozess kann die Datei bearbeiten. |
|
3 |
LOCK_NB |
Zugriff non-blocking: Ist die Datei bereits gepsperrt, dann fährt der aktuelle Prozess mit der nächsten Anweisung fort, ohne auf die freigabe der Datei zu warten |
|
4 |
LOCK_UN |
unlock: Der aktuelle Prozess hebt die Dateisperre wieder auf. |
|
Name |
Bedeutung |
|---|---|
|
$. oder $INPUT_LINE_NUMBER |
Zeilennummer der zuletzt eingelesenen Zeile |
|
$/ oder $INPUT_RECORD_SEPARATOR |
Datensatztrennzeichen, die beim Einlesen mit <DATENSTROM> verwendet werden. |
Schreiben Sie ein Script, welches aus einem CSV- File eine Spalte mit der Nummer i extrahiert und in eine Datei kopiert. (CSV- Kandidat z.B. c:\windows\pfirewall.log)
Schreiben Sie ein Script, welches ein gegebenes
Unterverzeichnis durch alle Subverzeichnisse durchläuft, und
dabei für jede gefundene Datei folgende Datensatz in eine
Protokolldatei rausschreibt: <Pfad + Dateiname>
<Dateigröße in Byte>\n
Dokumentation: http://perldoc.perl.org/DirHandle.html, http://perldoc.perl.org/File/Find.html
Perl bietet einen Satz eingebauter Fuktionen, um Dateiverzeichnisse zu verwalten. Möchte man alle Einträge in einem Verzeichnis auslesen, so muß dieses zu Begin als Resource geöffnet werden, auf die dann über eine Verzeichnishandle zugegriffen werden kann:
# Verzeichnis öffnen my $dir = 'C:\Programme\Adobe'; my $dirhand = gensym(); opendir($dirhand, $dir) or die "Verzeichnis $dir existiert nicht\n";
Alle Einträge des Verzeichnisses können anschliessend eingelesen werden:
# Alle Verzeichniseinträge einlesen
my @eintraege = readdir($dirhand);
my $CntDirs = 0;
my $CntFiles = 0;
# Für Unterverzeichniseinträge:
for (my $i = 0; $i <= $#eintraege; $i++) {
# Verzeichnis- Testoperator: Prüfen, ob der Eintrag der Name eines Verzeichnises ist
if (-d "$dir/$eintraege[$i]") {
# Nur die Unterverzeichnisse zählen
if ($eintraege[$i] ne '.' and $eintraege[$i] ne '..') {
# Zähler für Unterverzeichnisse incrementieren
CntDirs++;
}
} # Dateitestoperator
elsif (-f "$dir/$eintraege[$i]") {
# Zähler für Datei incrementieren
CntFiles++;
}
}Dokumentation: http://perldoc.perl.org/File/stat.html
Mittels des Befehls stat können alle Dateiattribute einer Date in einem Verzeichnis gelesen werden:
# Attribute der Datei auslesen
my ($dev,
$inode,
$mode,
$nlink,
$uid,
$gid,
$rdev,
$size,
$atime,
$mtime,
$ctime,
$blksize,
$blocks) = stat("$path/$fname");Dokumentation: http://perldoc.perl.org/perlmod.html
Packages entsprechen den Namespaces von C++. Alle in einem Package eingeschlossenen Namen können außerhalb eines Packages angesprochen werden, wenn ihnen das Namespräfix des Packages durch den :: Operator vorangestellt wird.
$x = 1; package mko; $x = 2; package main; print $x; # Ergebnis ist 1 print $mko::$x; # Ergebnis ist 2
Dokumentation: http://perldoc.perl.org/perlobj.html
Klassen werden in Perl durch Packages deklariert, die eine spezielle Prozedur, den Konstruktor enthalten. Der Konstruktor hat nach allgemeiner Konvention den Namen new.
Der Konstruktor erzeugt ein annonymes Hash, in welcher durch die Systemfunktion bless die Datenelemente und Methoden des neuen Objektes mittels Referenzen verzeichnet werden.
package Cauto;
sub new {
# Konstruktor
my $classname = shift;
my $self;
# leeres, annonymes Hash als Speicher für Instanzdaten
$self = {};
# Deklaration und Initialiseirung der Datenelemente
$self-> {Marke} = "";
$self-> {Farbe} = "";
$self-> {Motorleistung_PS} = 0;
# Verbinden mit den Instanzmethoden
bless $self, $classname;
return $self;
}Methoden einer Klasse werden als gewöhnliche Funktionen in einem Klassen- package definiert. Im ersten Parameter wird stets die Referenz auf das Objekt übergeben. Es ist eine Konvention, diese aus dem ersten Parameter in der lokalen $self zu sichern. Über $self kann dann auf die Datenelemente und Funktionen der Instanz zugegriffen werden.
package Cauto;
:
sub set_velocity {
# Methode
($self, $vel_new) = @_;
$self-> {velocitiy} = $vel_new;
}Es gibt zwei Schreibweisen für den Aufruf von Methoden:
<methodenname> (<Referenz von Instanz> | <Klassenname>) <parameterliste>
$obj = new Cauto "Ferrari";
(<Referenz von Instanz> | <Klassenname>) '->' <methodenname> '(' <paramterliste> ')'
Cauto-> new("Ferrari");
Die erste Variante ist der klassische prozedurale Stil. Variante zwei entspicht dem neuzeitlichen objektorientierten Stil.
Implementieren Sie eine Klasse für die SI- Messwerte aus den Aufgaben des Kapitels Referenzen. Zusätzlich soll die Klasse die Memberfunktion GetVal enthalten, welche den Messwert gem. Scale skaliert zurückgibt.
Dokumentation: http://perldoc.perl.org/Cwd.html
Durch das Modul CWD wird die Funktion cwd bereitgestellt, welche das aktuelle Arbeitsverzeuchnis zurückgibt:
use CWD; print "aktuelles Arbeitsverzeichnis: ", cwd;
#!/usr/bin/perl -w
use strict;
use feature 'say';
use Digest::MD5;
my $md5 = Digest::MD5->new;
$md5->add("hallo");
say $md5->hexdigest;
$md5-> reset();
$md5->add("hallo");
say $md5->hexdigest;
say $md5->hexdigest;
$md5-> reset();
say $md5->hexdigest;
$md5->add("hallo");
say $md5->hexdigest;Dokumentation: http://perldoc.perl.org/Net/Domain.html
Bestimmen des Computernamens:
use feature 'say'; use Net::Domain; say &Net::Domain::hostname();
# IP- Adresse lesen
use Sys::Hostname;
use Net::hostent;
use Socket;
$host = hostname;
print "hostname $host\n";
$h = gethost($host);
#print "name $name,aliases $aliases,addrtype $addrtype,\n";
print $h-> name, "\n";
if ( @{$h->addr_list} > 1 ) {
my $i;
for $addr ( @{$h->addr_list} ) {
printf "\taddr #%d is [%s]\n", $i++, inet_ntoa($addr);
}
} else {
printf "\taddress is [%s]\n", inet_ntoa($h->addr);
}Dokumentation: http://perldoc.perl.org/Net/Ping.html
Ein Computer im Netz kann wie folgt angepingt werden:
use Net::Ping;
my $p = Net::Ping->new("icmp");
my $host ="www.trac.biz";
if($p->ping($host)) {
print "$host is alive.\n";
} else {
print "$host is not alive.\n";
}
$p->close();Dokumentation: http://perldoc.perl.org/Net/Time.html
Liste von Timeservern: http://timeserver.verschdl.de/
use Net::Time;
say "T= " . Net::Time->inet_time('atom.uhr.de', 'udp');
say "Fertig";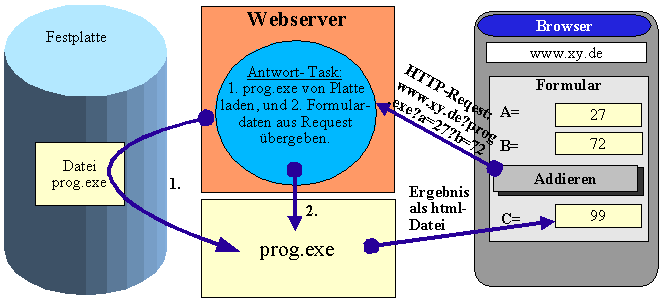
Mittels
des Moduls Net::HTTP::NB kann eine Webseite mittels Perl von einem
Webserver abgerufen werden:
#!/usr/bin/perl -w
use strict;
use feature 'say';
use Net::HTTP::NB;
my $client = Net::HTTP::NB->new(Host => "www.trac.biz") or die $@;
$client->write_request(GET => "/");
my $code;
my $mess;
my %h;
do {
($code, $mess, %h) = $client->read_response_headers;
} until($code);
my $txt = "";
while (1) {
my $buf;
my $n = $client->read_entity_body($buf, 1024);
last unless $n;
print $buf;
$txt .= $buf;
}Dokumentation: http://perldoc.perl.org/CGI.html
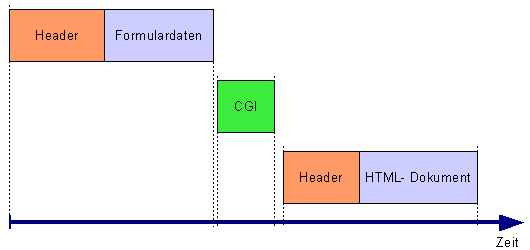
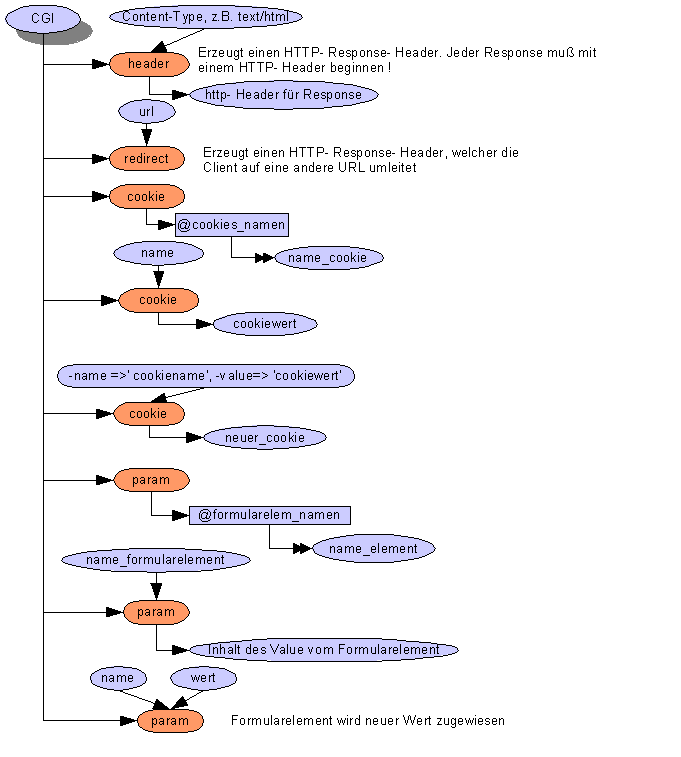
Im folgenden wird ein CGI- Script beschrieben, welche das HTML- Formular steuerelemente.html verarbeitet.
#!c:/perl/bin/wperl.exe
# Der Kommentar in der 1. Zeile verweist im Kontext des Webservers auf die Position des
# perl- Interpreters im Dateisystem
use diagnostics;
use strict;
use CGI;
# Puffer für die Ausgabe anlegen
my $buffer = "";
# cgi- Objekt anlegen, mit dem der http- Response aufgebaut wird
my $cgi = new CGI;
# 1) Am Anfang muß immer ein http- Header erzeugt werden
$buffer = $cgi-> header;
# 2) Kopf des HTML- Antwortdokumentes erzeugen
$buffer .= $cgi-> start_html(-title=>'Auswertung', -author=>'Martin Korneffel', -BGCOLOR=> '#99FF33');
# 3) Dokumentinhalt aufbauen
$buffer .= $cgi-> h1('Auswertung des Formulares');
# 3.1) Alle Liste der gesendeten Parameter (GET oder POST)
$buffer .= $cgi-> h2('Gesendete Formularelemente');
my @elemnamen = $cgi-> param();
$buffer .= $cgi-> p("@elemnamen");
# 3.2) Textbox auswerten
$buffer .= $cgi-> h2('Eingabe im Textfeld');
$buffer .= $cgi-> p($cgi-> param('tbx1'));
# 3.3) Listbox auswerten
$buffer .= $cgi-> h2('Auswertung einfache Listbox');
$buffer .= $cgi-> p($cgi-> param('lbx1'));
# 3.4) Multilistbox auswerten
$buffer .= $cgi-> h2('Auswertung einfache Listbox');
my @mbxSel = $cgi-> param('mbx1');
# 3.4.1) Anzeige der Selektionen in einer nummerierten Liste
$buffer .= $cgi-> start_ol;
foreach my $val (@mbxSel) {
$buffer .= $cgi-> li($val);
}
$buffer .= $cgi-> end_ol;
# 3.5) Checkbox auswerten
$buffer .= $cgi-> h2('Auswertung der Checkbox');
my @cbxSel = $cgi-> param('cbx1');
# 3.5.1) Ausgabe der angehakten Boxen in einer nummerierten Liste
$buffer .= $cgi-> start_ol;
foreach my $val (@cbxSel) {
$buffer .= $cgi-> li($val);
}
$buffer .= $cgi-> end_ol;
# 3.6) URL's manipulieren
$buffer .= $cgi-> h2('Eigene URL bestimmen und manipulieren');
my $url = $cgi-> url(-full=>1, -path_info=>1);
$buffer .= $cgi-> p($url);
# URL des Rufers berechnen
$url =~ s/(steuerelemente\-auswertung\.pl)/steuerelemente.html/;
$buffer .= $cgi-> p($url);
# 3.7) Zurück- Hyperlink aufbauen
$buffer .= $cgi-> hr();
$buffer .= $cgi-> start_p();
$buffer .= $cgi-> a({href=>"$url"}, 'Zurück'),
$buffer .= $cgi-> end_p();
# 3.8) HTML- Dokument abschliessen
$buffer .= $cgi-> end_html;
# 4) Den Response an den Browser senden
print $buffer;
# EndeDokumentation: http://cpan.uwinnipeg.ca/chapter/Database_Interfaces/DBD
#Anzeige aller DBD- Treiber
my @listOfDbdDriver = DBI->available_drivers;
foreach my $drv (@listOfDbdDriver) {
print $drv, "\n";
}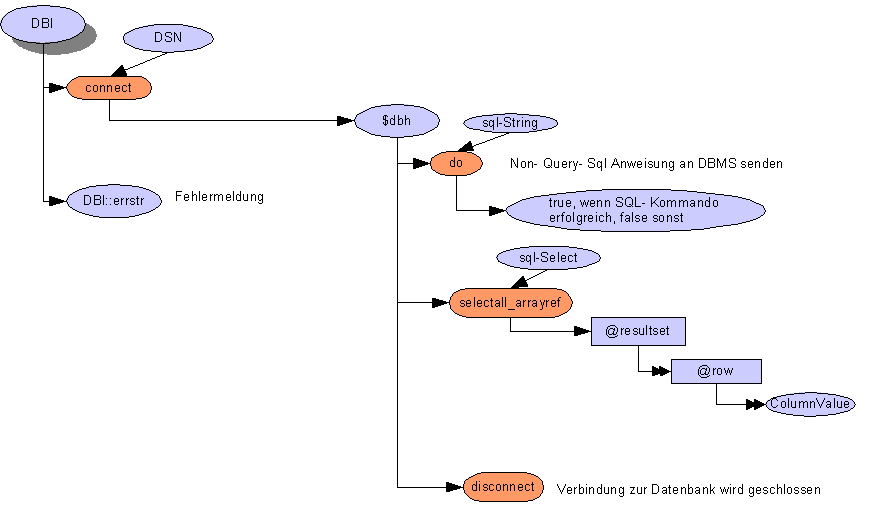
# Definieren der Verbindungsinformationen
my $server_name = ".";
my $database_name = "dmsmin";
my $user = "Schüler1";
my $password = "sql";
my $DSN = "driver={SQL Server};Server=$server_name; database=$database_name;uid=$user;pwd=$password;";
# Verbinden mit dem Datenbankserver
my $dbh = DBI->connect("dbi:ODBC:$DSN") or die "$DBI::errstr\n";
# Abrufen aller Datensätze und Kopieren in eine Arraystruktur
my $res = $dbh-> selectall_arrayref("select * from dbo.FileTypeSizeTop15View") or die DBI::errstr;
$dbh-> disconnect();
# Anzahl der gefundenen Datensätze ausgeben
print $#$res, "\n";
# Ausgeben der 1. Spalte im 1. Datensatz
print $res->[0]->[0], "\n";
# Ausgeben aller Datensätze
foreach my $row (@$res) {
foreach my $col (@$row) {
print "$col\t";
}
print "\n";
}my $now = VBtime::toODBC(VBtime::now());
say $now;
$dbh-> do(q{insert into data.EventLog (EventLogType_Id, created, author, log) values (3, ?, ?, ?)},
undef,
(
$now,
'perl',
q{<perl><msg>Hallo</msg></perl>}
)
) or die $dbh->errstr;
|
Modul |
Inhalt |
|---|---|
|
Win32::ChangeNotify |
Überwachen von Dateiänderungen |
|
Win32::EventLog |
Lesen und Schreiben in das Ereignisprotokoll |
|
Win32::NetAdmin |
Bestimmen des Domänecontrollers; Verwalten von Benutzerkonten und Gruppen |
|
Win32::NetResource |
Verwalten von Freigaben |
|
Win32::Process |
Erzeugen, Terminieren, anhalten und beenden von Prozessen |
|
Win32::Registry |
Anzeigen und ändern von Registrieungsschlüsseln |
|
Win32::Service |
Abfragen und steuern von Prozessen |
#! Perl
#
# 23.11.2003
# Martin Korneffel
use Win32::NetAdmin qw(GetUsers LoggedOnUsers UserGetAttributes);
my @users;
GetUsers($ENV{ComputerName}, FILTER_NORMAL_ACCOUNT, \@users);
foreach $user (@users) {
print "Benutzer $user\n";
}
print "Eingeloggte Benutzer\n";
LoggedOnUsers("", \@users);
foreach $user (@users) {
print "$user\n";
}
# Infos zu einem Benutzerkonto
UserGetAttributes("TRAC19", "Marina", $password, $passwordAge, $privilege, $homeDir, $comment, $flags, $scriptPath);
print "$password, $passwordAge, $privilege, $homeDir, $comment, $flags, $scriptPath";|
Nr |
Thema |
|---|---|
|
1 |
Geschichte von Perl und Allgemeines: http://de.wikipedia.org/wiki/Perl_(Programmiersprache) |
|
2 |
Perl- Plattform des O'Reilly Verlages : http://perl.com/ |
|
3 |
Persönliche Webseite von Larry Wall: http://www.wall.org/~larry/ |
|
4 |
Archiv von Scripten und Module: http://www.cpan.org/ |
|
5 |
Implementierungen für Perl unter Windows: http://www.activestate.com/index.mhtml |